In brief
- GPT Image 2 launched in late April with native reasoning and extremely good text accuracy in any script.
- Nano Banana 2 wins on anime illustration, aerial spatial composition, and structured information design.
- GPT Image 2 dominates on photorealism, typography, and signature calligraphy.
OpenAI recently launched GPT Image 2 with the kind of understatement reserved for people who know the results will speak for themselves. No keynote. No hype cycle. Just a model page, mostly a gallery, and an Image Arena score that put it 242 points ahead of every other model currently available—the largest lead ever recorded on the leaderboard.
The timing was pointed. When we last looked at the top end of AI image generation, Google’s Nano Banana 2 had just claimed the crown, and we pitted it against ByteDance’s Seedream 5 Lite in a seven-category shootout. Seedream held its own on price and spatial fidelity. Nano Banana 2 won on speed and text rendering. Then OpenAI walked in.
GPT Image 2—model identifier gpt-image-2, running on the GPT-5.4 backbone—is OpenAI’s first image model with native reasoning built into the architecture. Before it draws anything, it researches, plans, and reasons through the image structure.
OpenAI also retired DALL-E 3 and GPT Image 1.5, which are both being shut down on May 12. This isn’t an update—it’s a replacement.
We ran the same seven-category framework we used in the Nano Banana vs. Seedream comparison to see what actually changed—and whether Google’s current champion can hold the overall title.
What GPT Image 2 offers
The headline feature is text. OpenAI claims approximately 99% character-level accuracy across Latin, CJK, Hindi, and Bengali scripts. That’s not a modest improvement over prior models—text rendering has historically been the thing that makes AI image generators look like toys, with garbled signs, nonsense fonts, and letters that bleed into each other.
GPT Image 2 appears to have largely solved it.
The model supports up to 4K resolution and generates up to eight coherent images from a single prompt with consistent characters and objects maintained across the batch. That last part—batch consistency—is a new primitive for production workflows. Children’s book publishers and agencies running multi-format campaigns now have a tool that didn’t exist before now.
Access is tiered. Instant Mode brings the core quality jump to all ChatGPT users, including those on the free tier. Thinking Mode—where the model reasons, web-searches, and self-checks before generating—is restricted to Plus, Pro, and Business subscribers. The official API opens to developers in early May.
Until then, direct access runs through ChatGPT or third-party proxies at roughly $0.01–$0.03 per image. OpenAI’s token-based API pricing lands at $8 per million input tokens and $30 per million output image tokens—slightly cheaper than Nano Banana 2’s $60 per million output tokens at equivalent resolution tiers.
Testing GPT Image 2 vs Nano Banana 2: Which one wins?
Realism: The rooftop architect test
The prompt specified a cinematic portrait of a 32-year-old female architect at sunset, with constraints on coat color, glasses type, a roll of blueprint held in the right hand, golden hour lighting, a 50mm depth-of-field simulation, film grain, and a 4:5 vertical aspect ratio. Every element was an independent constraint that could fail.
GPT Image 2 produced an impressive result compared against its predecessor, however the stare from the subject has that typical AI mood that is sometimes easy to spot. The city skyline bokeh behaved like an actual 50mm f/1.8. The trench coat fabric had tactile weight. The skin showed natural freckled texture with real subsurface scattering rather than the smooth synthetic finish common in beauty-trained diffusion models. Blueprints held in the right hand as specified.

Nano Banana 2 produced a competent portrait that reads as composite. The sunset is a shade too saturated for the actual golden hour. The skin is also very natural for the resolution, but her stare looks more genuine and natural. There’s no film grain, however, and she is holding different blueprints instead of a single roll. The image is actually very similar as the one from previous tests, which shows the model lacks a bit of creativity when given different constraints.

Winner: Nano Banana 2
Art and painting: The Renaissance astronomer
This prompt demanded Rembrandt-adjacent art with three competing light sources—warm candle, cold moonlight, and a green bioluminescent jar—all mixing correctly across a cluttered stone observatory. It also required a specific list of desk objects, a cat with one white paw, and a visible oil brushstroke texture.
GPT Image 2 got the light physics right. Each source casts its own color temperature across surfaces. The velvet robe shows fraying at the cuffs, the skull is deployed as a bookend, the tome has what can be interpreted as handwritten text, and the black cat with a white paw is silhouetted against a comet sky. The whole thing reads like an actual oil painting, not a rendering.
However, GPT Image 2 showed one flaw that may be its curse until the next model comes out: When given too many parameters, the model oversharpens the image and generates a lot of artifacts that heavily decrease its quality. This is probably the equivalent to GPT Image 1’s derided “piss filter,” but for this new model generation.

Nano Banana 2 produced something beautiful—but in the wrong genre. It landed closer to high-end fantasy card illustration than oil painting. The painting is shallow, the tome text has actual letters but not legible script, and the cat has two white paws instead of one. The scene is overexposed, but the light sources are properly represented.

Winner: GPT Image 2
Illustration: The anime spirit medium
This is where Nano Banana 2 hits back hard. The prompt asked for an anime key visual in the style of Ufotable—the studio behind “Demon Slayer” and “Fate/Zero”—with specific technical requirements: cel shading with ink outline weight variation, a body slowly turning into energy, subsurface skin glow, a nine-tailed kitsune fox, ofuda talisman calligraphy in legible kanji, and a Makoto Shinkai painterly twilight background in violet, amber, and rose.
Nano Banana 2 delivered what might be the best single output of the entire seven-category evaluation. The cel shading has correct ink weight variation. The tails are luminous and clearly present. The ofuda kanji is recognizable. The twilight gradient is exact. The composition reads like a real theatrical poster.

GPT Image 2, by comparison, produced an anime pastiche. Clean outlines, correct energy dissolution effect, good cherry blossom bokeh—but the Ufotable subsurface skin glow is absent, and the nine-tailed kitsune is reduced to a single physical tail companion with other tails looking differently.
Again, in this art, the oversharpening and artifacts are apparent, and the image is not visually pleasing.

Winner: Nano Banana 2
Lettering and style understanding: The signature design test
Both models were shown reference examples from a professional lettering service—an ornate cursive signature style with controlled complexity—and asked to design a signature for “José Lanz” in that aesthetic: abstract but legible.
GPT Image 2 produced clean, fluid cursive with correct loop ascenders, rendered on textured paper with an embossed letterpress effect. It’s plenty legible as “José Lanz,” but stylized. The critique: It played it safe. The reference material is more energetically entangled than what GPT produced. But it’s a usable deliverable that properly emulates the reference.

Nano Banana 2 attempted to match the ornate complexity and produced illegible scrawl. The reference’s appeal is controlled chaos—loops that look wild but resolve into readable letterforms. Gemini got wild and lost legible. It also reproduced the service’s watermark, an IP concern in any professional context.

Winner: GPT Image 2, by a large margin
Spatial awareness: The steampunk aerial
This is a demanding composition prompt with instructions for different objects at specific locations: a vast steampunk clock tower city from a three-quarter aerial perspective, with five depth planes, an atmospheric haze gradient, and six specific readable text elements distributed across the scene—including four clock faces each showing different times in Roman numerals.
Nano Banana 2 edges this one. Its aerial geometry is more convincing—the three-quarter view actually reads as three-quarter rather than a tilted front view. The five depth planes are distinctly separated, atmospheric haze increases correctly with distance, and the wet cobblestone newspaper texture is excellent. The elements are properly represented and the text is readable but not all the lines appeared in the scene

GPT Image 2 got all six text elements right and all clock faces correct, but the depth planes partially collapse in the mid-ground, and the clock tower showed four clocks with different times. It also represented the text more accurately—for example, the gargoyle showed the document that reads “Sector 7: Condemned,” which Nano Banana Pro didn’t represent.
Again, the large number of parameters to take into consideration seems to have degraded the image quality, triggering the oversharpening effect, similar to using a LoRA in Stable Diffusion with too much presence.

Winner: Nano Banana 2
Lettering density: The Kellerman’s Hardware scene
The most punishing text-recall test: a gritty urban intersection at 2 a.m. where every surface carries readable copy—a ghost sign, graffiti in chrome bubble letters, vinyl storefront lettering, a concert poster with a barcode, a torn reveal underneath, embossed metal awning letters, cardboard handwriting, stenciled curb text, and a sticker-bombed payphone with specific copy including “ANSWERS TO MOCHI.”
GPT Image 2 delivered near-perfect element recall. Every specified text element was present and readable. The ghost sign drop-shadow fade and peel texture was exceptional. The sodium vapor color cast was accurate—that specific green-amber of actual sodium vapor streetlights, not generic amber. Wet asphalt reflections were convincing.

Nano Banana 2 also performed strongly, but lost some specificity. The “STILL HERE” graffiti used outline bubble letters instead of chrome-fill. The torn poster reveal was partial. The sodium vapor cast was more generic. Several elements from the prompt didn’t survive the render. Still, visually it was a more pleasing image than what GPT Image 2 produced because of its oversharpening flaw.

Winner: GPT Image 2, because of the prompt adherence
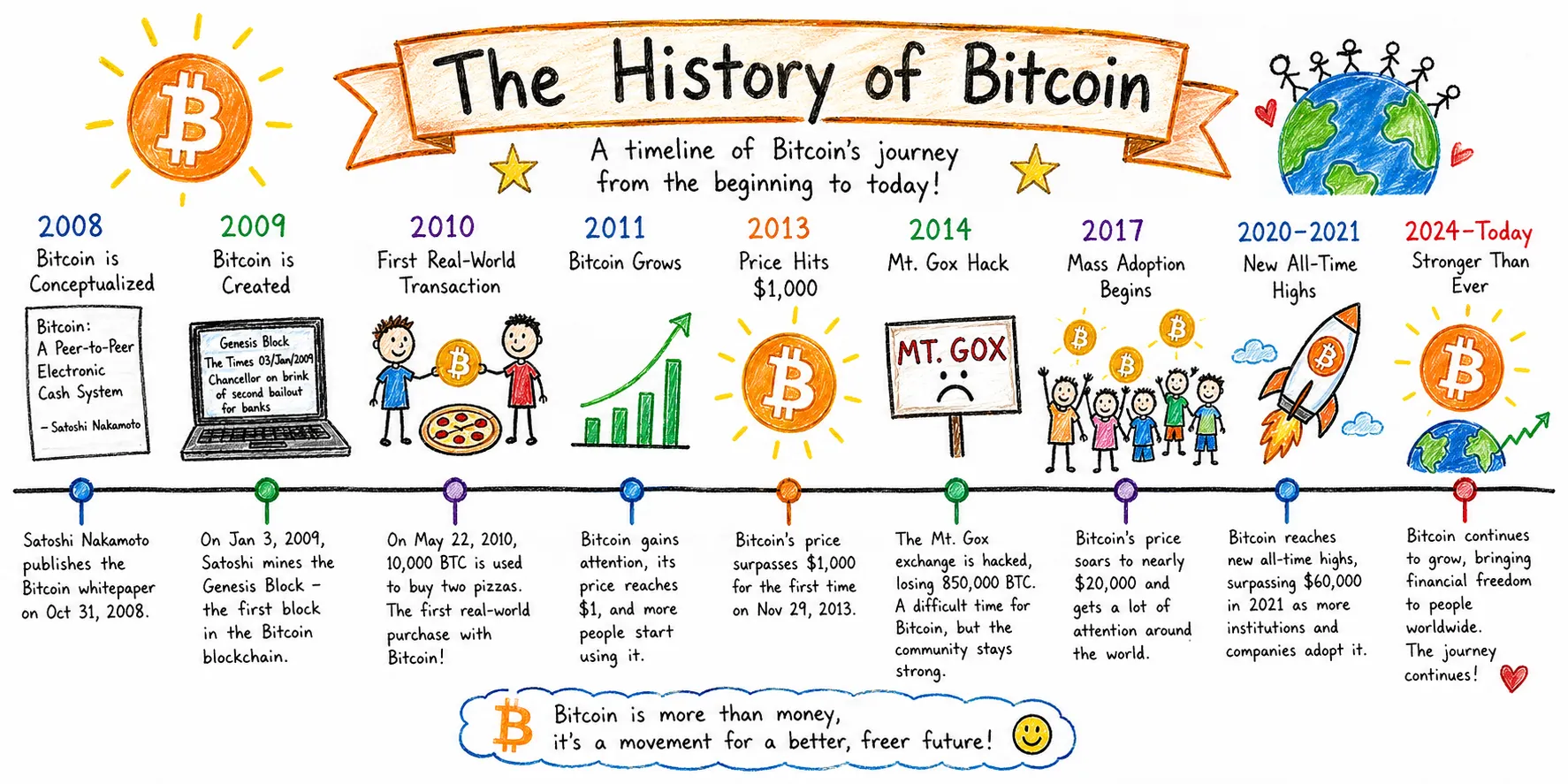
Agentic research: The Bitcoin timeline
This category tests something different—not rendering quality, but editorial judgment and information architecture. Both models have the capability to activate an agent for research and investigation before rendering an image, so we compared both models.
The prompt asked for a widescreen Bitcoin history timeline in kids-drawing style, with a strict quality bar on information accuracy.
GPT Image 2 treated it like an infographic commission. The output uses a horizontal timeline with color-coded year markers, illustration slots above, and explanatory text below each event. Dates are specific: October 31, 2008 for the white paper; January 3, 2009 for the genesis block; May 22, 2010 for Pizza Day. The Mt. Gox entry correctly cites 850,000 BTC lost. Events are evenly distributed from 2008 to 2024.
Nano Banana 2’s output is more charming—a winding road metaphor for Bitcoin’s volatile journey is genuinely clever—but the first-person title “My Bitcoin Timeline” is odd for an informational piece. The 2020–2024 section is visually congested, and information density is uneven across eras.
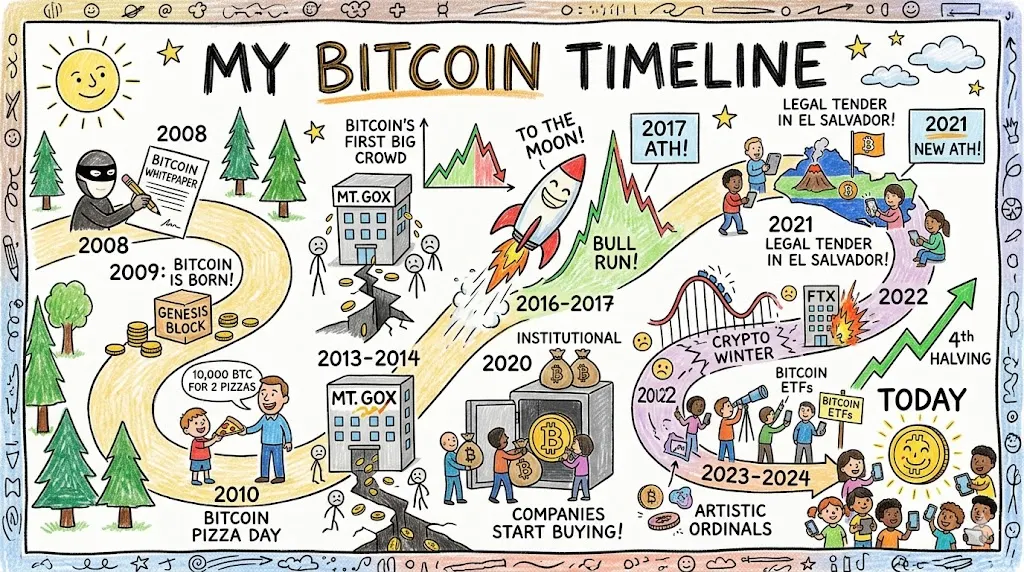
Verdict: It’s a tie. Nano Banana is more visually pleasing, but GPT Image 2 has more information in the output
Image editing: Living room redesign
This test measures something distinct from pure generation: how well a model reads an existing space and transforms it while staying anchored to that specific room. It’s closer to what a staging app or an interior architect tool needs to do.
Prompt: Here is a photo of my living room. Make it more modern and minimalistic. change the floor for a marble white one, use mirrors in a cohesive style to decorate the front wall, and make the overall aesthetic modern and more pleasing to the eyes:

GPT Image 2’s output is immediately recognizable as the room. The door is in the same position. The smart lock is there. The wall art arrangement, the hanging plant, the shelf—all preserved.
The model’s redesign choices are also genuinely good for what it was prompted: It replaced the mixed mirror arrangement with a lit triptych that creates a focal wall, and the warm LED halo behind the panels is a real interior design technique. The reflections on the mirror actually match the references, which is an interesting implementation.
However, it didn’t implement changes on the floor.

Gemini’s output looks more realistic due to the lighting, but has a more chaotic relationship with the source. It took the “use mirrors” instruction way too literally, and put mirrors on mirrors, for example. The mixed frame styles (some gold, some brass, different shapes) also contradict the “cohesive style” instruction specifically.
It seems as if the model applied an inpainting layer on the specific areas that it marked as editable. The perspective is also slightly off.

Winner: GPT Image 2 because of the choices. It’s easier to change individual things iteratively than instructing Gemini to change all the elements it created
Verdict
GPT Image 2 wins in most categories: realism, classical art, signature calligraphy, image editing, and lettering density. Nano Banana 2 wins in anime illustration, spatial composition, and structured information design. However, it is the most consistent model when it comes to longer prompts.
Overall, as long as you give ChatGPT enough creative freedom to avoid triggering the sharpening effect, the results will be aesthetically pleasing, realistic, and strong with text. However, the models are so close in quality that a good prompting strategy may change the outcomes in favor of each one.
GPT Image 2 may be the easiest model to approach from scratch, but Nano Banana 2, with a proper prompting technique and iterations, will produce outstanding results that may look more professional and polished depending on the use case.
Daily Debrief Newsletter
Start every day with the top news stories right now, plus original features, a podcast, videos and more.